Java 11's release candidate is already here, and the industry is still roaming around Java 8. Every six months, we will see a new release. It is good that Java is evolving at a fast speed to catch up the challengers, but at the same time, it is also scary to catch its speed, even the Java ecosystem (build tools, IDE, etc.) is not catching up that fast. It feels like we are losing track. If I can't catch up with my favorite language, then I will probably choose another one, as it is equally as good to adapt to the new one. Below, we will discuss some of the useful features from Java 8, 9 and 10 that you need to know before jumping into Java 11.
Before Java 8? Too Late!
Anyone before Java 8? Unfortunately, you will need to consider yourself out of the scope of this discussion — you are too late. If you want to learn what's new after Java 7, then Java is just like any new language for you!
Java 8: A Tradition Shift
Java 8 was released four years ago. Everything that was new in Java 8 has become quite old now. The good thing is that it will still be supported for some time in parallel to the future versions. However, Oracle is already planning to make its support a paid one, as it is the most used and preferred version to date. Java 8 was a tradition shift, which made the Java useful for today and future applications. If you need to talk to a developer today, you can't just keep talking about OOP concepts — this is the age of JavaScript, Scala, and Kotlin, and you must know the language of expressions, streams, and functional interfaces. Java 8 came with these functional features, which kept Java in the mainstream. These functional features will stay valuable amongst its functional rivals, Scala and JavaScript.
A Quick Recap
Lambda Expression: (parameters) -> {body}
Lambda expressions opened the gates for the functional programming lovers to keep using Java. Lambda expressions expect zero or more parameters, which can be accessed in the expression body and returned with the evaluated result.
Functional Interface: an Interface With Only one Method
The lambda expression is, itself, treated as a function interface that can be assigned to the functional interface, as shown above. Java 8 has also provided a new functional construct shown below:
Refer to the package
java.util.function for more functional constructs: Function, Supplier, Consumer, Predicate, etc. One can also define the functional interface using @FunctionalInterface.
Interfaces may also have one or more default implementations for a method and may still remain as a functional interface. It helps avoid unnecessary abstract base classes for default implementation.
Static and instance methods can be accessed with
:: operator, and constructors may be accessed with ::new, and they can be passed as a functional parameter, e.g. System.out::println.Streams: Much More Than Iterations
Streams are a sequence of objects and operations. A lot of default methods have been added in the interfaces to support
forEach, filter, map , and reduce constructs of the streams. Java libraries, which were providing collections, now support the streams. e.g. BufferredReader.lines(). All the collections can be easily converted to streams. Parallel stream operations are also supported, which distributes the operations on the multiple CPUs internally.Intermediate Operations: the Lazy Operation
For intermediate operations performed lazily, nothing happens until the terminating operation is called.
map (mapping): Each element is one-to-one and converted into another form.filter (predicate): filter elements for which the given predicate is true.peek () , limit(), and sorted () are the other intermediate operations.Terminating Operations: the Resulting Operations
forEach (consumer): iterate over the each element and consume the elementreduce (initialValue, accumulator): It starts with initialValue and is iterated over each element and kept updating at a value that is eventually returned.collect (collector): this is a lazily evaluated result that needs to be collected using collectors, such as java.util.stream.Collectors, including toList(), joining(), summarizingX(), averagingX(), groupBy(), and partitionBy().Optional: Get Rid of the Null Programming
Null-based programming is considered bad, but there was hardly any option to avoid it earlier. Instead of testing for null, we can now test for
isPresent() in the optional object. Read about it — there are multiple constructs and operations for streams as well, which returns optional.JVM Changes: PermGen Retired
The
PermGen has been removed completely and replaced by MetaSpace. Metaspace is no more part of the heap memory, but of the native memory allocated to the process. JVM tuning needs different aspects now, as monitoring is required, not just for the heap, but also for the native memory.
Some combinations of GCs has deprecated. GC is allocated automatically based on the environment configurations.
There were other changes in NIO, DateTime, Security, compact JDK profiles, and tools like jDeps, jjs, the JavaScript Engine, etc.
Java 9: Continue the Tradition
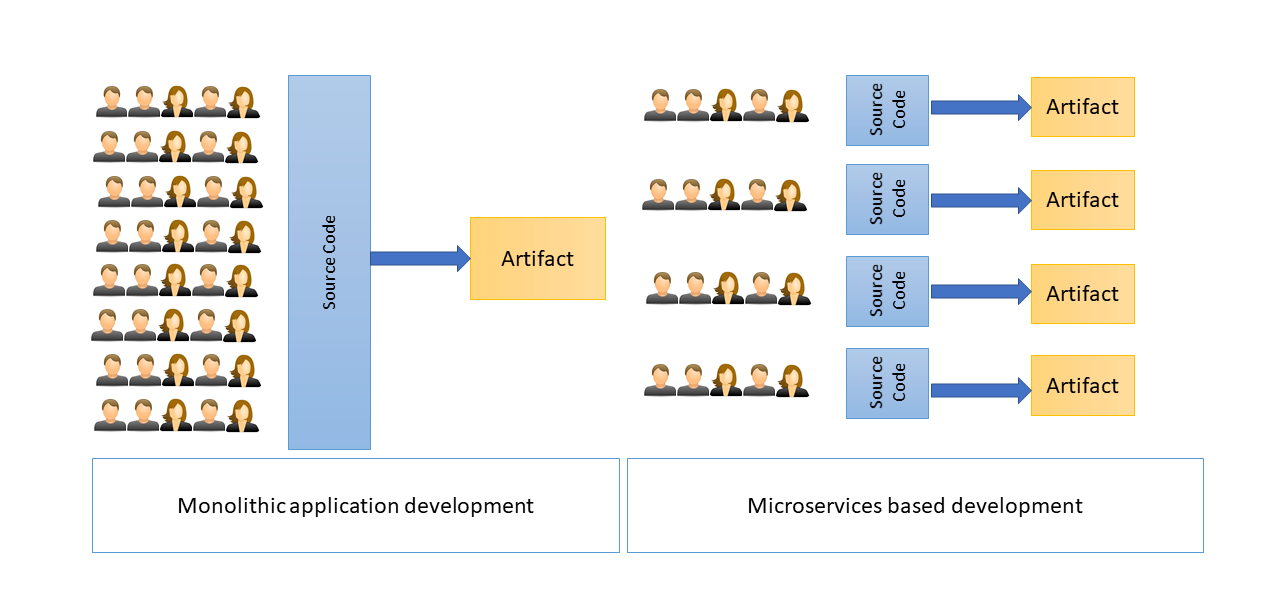
Java 9 has been around us for more than a year now. Its key feature module system is still not well adapted. In my opinion, it will take more time to really adopt such features in the mainstream. It challenges developers in the way they design classes. They now need to think more in terms of application modules than just a group of classes. Anyway, it is a similar challenge to what a traditional developer faces through microservice-based development. Java 9 continued adding functional programming features to keep Java alive and also improved JVM internals.
Java Platform Module System: Small Is Big
The most known feature of Java 9 is the Java Platform Module System (JPMS). It is a great step towards the real encapsulation. Breaking a bigger module in small and clear modules consists of closely related code and data. It is similar to an OSGi bundle, where each bundle defines dependencies it consumes and exposes things on which other modules depend.
It introduces an assemble phase between compile and runtime that can build a custom runtime image of JDK and JRE. Now, JDK itself consists of modules.
These modules are called system modules. A jar loaded without a module information is loaded in an unnamed module. We can define our own application module by providing the following information in file
module-info.java:
requires — dependencies on other modules
exports — export public APIs/interfaces of the packages in the module
opens — open package for reflection access
uses — similar to requires.
exports — export public APIs/interfaces of the packages in the module
opens — open package for reflection access
uses — similar to requires.
To learn more, here is a quick start guide.
Here are the quick steps in the IntelliJ IDE:
1. Create Module in IntelliJ: Go to File > New > Module - "first.module"
2. Create a Java class in /first.module/src
4. Add
module-info.java : /first.module/src > New > package 
5. Similarly, you need to create another module "
main.module " and Main.java:
6. IntelliJ automatically compiles it and keeps a record of dependencies and
--module-source-path
7. To run the
Main.java, it needs --module-path or -m:
So, this way, we can define the modules. Java 9 comes with many additional features. Some of the important ones are listed below
Catching up With the Rivals
Reacting Programming — Java 9 has introduced
reactive-streams, which supports React, like async/await communication between publisher and consumers. It added the standard interfaces in the Flow class.
JShell – the Java Shell - Just like any other scripting language, Java can now be used as a scripting language.
Stream and Collections enhancement: Java 9 added a few APIs related to "ordered" and "optional" stream operations.
of() operation is added to ease up creating collections, just like JavaScript. Self-Tuning JVM
G1 is made the default GC, and there have been improvements in the self-tuning features in GC. CMS has been deprecated.
Access to Stack
The
StackWalker class is added to lazy access to the stack frames, and we can traverse and filter into it.Multi-Release JAR Files: MRJAR
One Java program may contain classes compatible with multiple versions. To be honest, I am not sure how useful this feature might be.
Java 10: Getting Closer to the Functional Languages
Java 10 comes with the old favorite
var of JavaScript. You can not only declare types of free variables but you can also construct the collection type free. The following are valid in Java:
The code is getting less verbose and the magic of scripting languages is getting added in Java. It will definitely bring the negatives of these features to Java, but it has given a lot of power to the developer.
More Powerful JVM
This was introduced in parallelism in the case that full GC happens for G1 to improve the overall performance.
Heap allocation can be allocated on an alternative memory device attached to the system. It will help prioritize Java processes on the system. The low priority one may use a slow memory as compared to the important ones.
java 10 also Improved thread handling in handshaking the thread locally. Ahead-Of-Time compilation (experimental) was also added. Bytecode generation enhancement for loops was another interesting feature with Java 10.
Enhanced Language
In Java 10, we Improved Optional, unmodifiable collections API’s.
Conclusion
We have seen the journey from Java 8 to Java 10 and the influence of other functional and scripting languages in Java. Java is a strong object-oriented programming language, and at the same time, now it supports a lot of functional constructs. Java will not only bring top features from other languages, but it will also keep improving the internals. It is evolving at a great speed, so stay tuned — before it phases you out! Because, Java 11, 12 are on the way!